databasedev.co.uk - database solutions and downloads for microsoft access
Microsoft Access Articles
- General Microsoft Access Articles
- Microsoft Access 2007 Articles
- Tables
- Queries
- SQL
- Forms
- Reports
- Macros
- Modules & VBA
- Data Models
- Downloads
GUI Design
Resources
Online Shop
Info
Designer
for Microsoft Access
Create complex MS Access databases without being an expert in relational
database design! Designer for Microsoft Access asks you plain-language
questions about what you want to manage with your database, and creates
the tables and relationships automatically. Free trial available
Relational Database Design
The Relational Database Design Process:
One of the best ways to understand database design is to start with an all-in-one, flat-file table design and then toss in some sample data to see what happens. By analysing the sample data, you’ll be able to identify problems caused by the initial design. You can then modify the design to eliminate the problems, test some more sample data, check for problems, and re-modify, continuing this process until you have a consistent and problem-free design. Once you grow accustomed to the types of problems poor table design can create, hopefully you’ll be able to skip the interim steps and jump immediately to the final table design.
A sample design process
Let’s step through a sample database design process. We’ll design a database to keep track of students’ sports activities. We’ll track each activity a student takes and the fee per semester to do that activity.
Step 1: Create an Activities table containing all the fields: student’s name, activity and cost. Because some students take more than one activity, we’ll make allowances for that and include a second activity and cost field. So our structure will be: Student, Activity 1, Cost 1, Activity 2, Cost 2
Step 2: Test the table with some sample data. When you create sample data, you should see what your table lets you get away with. For instance, nothing prevents us from entering the same name for different students, or different fees for the same activity, so do so. You should also imagine trying to ask questions about your data and getting answers back (essentially querying the data and producing reports). For example, how do I find all the students taking tennis?
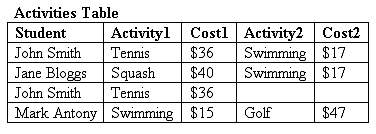
Step 3: Analyse the data. In this case, we can see a glaring problem in the first field. We have two John Smiths, and there’s no way to tell them apart. We need to find a way to identify each student uniquely.
Uniquely identify records
Let’s fix the glaring problem first, then examine the new results.
Step 4: Modify the design. We can identify each student uniquely by giving each one a unique ID, a new field that we add, called ID. We scrap the Student field and substitute an ID field. Note the asterisk (*) beside this field in the table below: it signals that the ID field is a key field, containing a unique value in each record. We can use that field to retrieve any specific record. When you create such a key field in a database program, the program will then prevent you from entering duplicate values in this field, safeguarding the uniqueness of each entry.
Our table structure is now: ID, Activity 1, Cost 1, Activity 2, Cost 2 While it’s easy for the computer to keep track of ID codes, it’s not so useful for humans. So we’re going to introduce a second table that lists each ID and the student it belongs to. Using a database program, we can create both table structures and then link them by the common field, ID. We’ve now turned our initial flat-file design into a relational database: a database containing multiple tables linked together by key fields. If you were using a database program that can’t handle relational databases, you’d basically be stuck with our first design and all its attendant problems. With a relational database program, you can create as many tables as your data structure requires.
The Students table would normally contain each student’s first name, last name, address, age and other details, as well as the assigned ID. To keep things simple, we’ll restrict it to name and ID, and focus on the Activities table structure.
Step 5: Test the table with sample data.
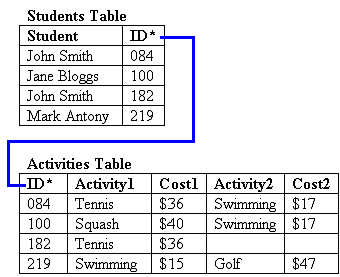
Step 6: Analyse the data. There’s still a lot wrong with the Activities table:
- Wasted space. Some students don’t take a second activity, and so we’re wasting space when we store the data. It doesn’t seem much of a bother in this sample, but what if we’re dealing with thousands of records?
- Addition anomalies. What if #219 (we can look him up and find it’s Mark Antony) wants to do a third activity? School rules allow it, but there’s no space in this structure for another activity. We can’t add another record for Mark, as that would violate the unique key field ID, and it would also make it difficult to see all his information at once.
- Redundant data entry. If the tennis fees go up to $39, we have to go through every record containing tennis and modify the cost.
- Querying difficulties. It’s difficult to find all people doing swimming: we have to search through Activity 1 and Activity 2 to make sure we catch them all.
- Redundant information. If 50 students take swimming, we have to type in both the activity and its cost each time.
- Inconsistent data. Notice that there are conflicting prices for swimming? Should it be $15 or $17? This happens when one record is updated and another isn’t.
Eliminate recurring fields
The Students table is fine, so we’ll keep it. But there’s so much wrong with the Activities table let’s try to fix it in stages.
Step 7: Modify the design. We can fix the first
four problems by creating a separate record for each activity a student
takes, instead of one record for all the activities a student takes.
First we eliminate the Activity 2 and Cost 2 fields. Then we need
to adjust the table structure so we can enter multiple records for
each student. To do that, we redefine the key so that it consists
of two fields, ID and Activity. As each student can only take an activity
once, this combination gives us a unique key for each record.
Our Activities table has now been simplified to: ID, Activity, Cost. Note how the new structure lets students take any number of activities – they’re no longer limited to two.
Step 8: Test sample data.
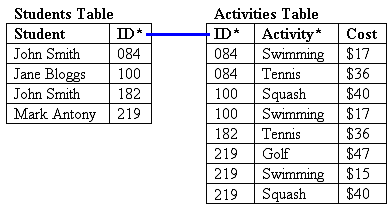
Step 9: Analyse the data. We know we still have the problems with redundant data (activity fees repeated) and inconsistent data (what’s the correct fee for swimming?). We need to fix these things, which are both problems with editing or modifying records.
Eliminate data entry anomalies
As well, we should check that other data entry processes, such as
adding or deleting records, will function correctly too.
If you look closely, you’ll find that there are potential problems
when we add or delete records:
- Insertion anomalies. What if our school introduces a new activity, such as sailing, at $50. Where can we store this information? With our current design we can’t until a student signs up for the activity.
- Deletion anomalies. If John Smith (#182) transfers to another school, all the information about golf disappears from our system, as he was the only student taking this activity.
Step 10: Modify the design. The cause of all our
remaining problems is that we have a non-key field (cost) which is
dependent on only part of the key (activity). Check it out for yourself:
The cost of each activity is not dependent on the student’s
ID, which is part of our composite key (ID + Activity). The cost of
tennis, for example, is $36 for each and every student who takes the
sport – so the student’s ID has no bearing on the value
contained in this field. The cost of an activity is purely dependent
on the activity itself. This is a design no-no, and it’s causing
us problems. By checking our table structures and ensuring that every
non-key field is dependent on the whole key, we will eliminate
the rest of our problems.
Our final design will thus contain three tables: the Students table
(Student, ID), a Participants table (ID, Activity), and a modified
Activities table (Activity, Cost). If you check these tables, you’ll
see that each non-key value depends on the whole key: the student
name is entirely dependent on the ID; the activity cost is entirely
dependent on the activity. Our new Participants table essentially
forms a union of information drawn from the other two tables, and
each of its fields is part of the key. The tables are linked by key
fields: the Students table:ID corresponds to the Participants table:ID;
the Activities table:Activity corresponds to the Participants table:Activity.
Step 11: Test sample data.

Step 12: Analyse the results. This looks good:
- No redundant information. You need only list each activity fee once.
- No inconsistent data. There’s only one place where you can enter the price of each activity, so there’s no chance of creating inconsistent data. Also, if there’s a fee rise, all you need to do is update the cost in one place.
- No insertion anomalies. You can add a new activity to the Activities table without a student signing up for it.
- No deletion anomalies. If John Smith (#219) leaves, you still retain the details about the golfing activity.
Keep in mind that to simplify the process and focus on the relational aspects of designing our database structure, we’ve placed the student’s name in a single field. This is not what you’d normally do: you’d divide it into firstname, lastname (and initials) fields. Similarly, we’ve excluded other fields that you would normally store in a student table, such as date of birth, address, parents’ names and so on.
A summary of the design process
Although your ultimate design will depend on the complexity of your data, each time you design a database, make sure you do the following:
- Break composite fields down into constituent parts. Example: Name becomes lastname and firstname.
- Create a key field which uniquely identifies each record. You may need to create an ID field (with a lookup table that shows you the values for each ID) or use a composite key.
- Eliminate repeating groups of fields. Example: If your table contains fields Location 1, Location 2, Location 3 containing similar data, it’s a sure warning sign.
- Eliminate record modification problems (such as redundant or inconsistent data) and record deletion and addition problems by ensuring each non-key field depends on the entire key. To do this, create a separate table for any information that is used in multiple records, and then use a key to link these tables to one another.